Теперь можно открыть её в VS Code и писать код или работать с данными, используя выделенные ресурсы. Скачиваем verl из github

Как мы с помощью Dev Cluster шерим GPU между ML-специалистами
Рассказываем о Dev Cluster — новом инструменте, с помощью которого можно удобно распределять ресурс GPU между ML-инженерами Яндекса.
4 июня 2026 г.
15 минут чтения
Привет! Меня зовут Аркадий, я руководитель команды инфраструктуры обучения Alice AI. В этой статье расскажу про инструмент Dev Cluster, который позволяет нам гибко распределять GPU между всеми ML-разработчиками подразделения. Это решение команды ML Platform из Yandex Infrastructure, в которой я раньше работал. Одна из главных задач этой команды — создавать инфраструктурные инструменты, которые ускоряют разработку и обучение ML-моделей. Подробности о том, как мы пришли к этому решению, как с помощью Dev Cluster запускать эксперименты на CPU и GPU, а также как быстро переключаться между разными конфигурациями железа, ищите в этой статье.
Вызовы машинного обучения: как пошерить GPU на всех
За последние 10 лет в мире случился взрывной рост в сфере машинного обучения. Если в 2012 году для обучения мощной модели требовалось несколько штук GPU, то сейчас бигтехам нужны тысячи GPU.
Надо понимать, что кроме самого железа нужно управлять ещё и огромным слоем софта, предназначенного для разработки и обучения на GPU. В отличие от цены классических виртуальных машин на CPU, цена виртуальной машины с GPU в 100 раз выше. В бигтехах уже не раздают GPU всем желающим — это нерационально.
Возникает идея: придумать shared-сервис, с помощью которого можно будет распределять дефицитный ресурс GPU между ML-инженерами. Практика показывает, что принцип работы с общими графическими процессорами отличается от совместного использования обычных предметов, таких как электросамокаты или автомобили. В этой статье расскажу, как мы в Yandex Infrastructure решали проблему комфортного доступа ML-инженеров к GPU.
Коммунальные виртуалки. Эврика! Или нет?
ML-специалисты, как и все разработчики, пишут довольно много кода, но, в отличие от классического бэкенда или фронтенда, этот код исполняется на GPU. Это создаёт несколько проблем.
-
Дорого.
Если вы зайдёте в любое облако и попробуете накликать себе виртуалку с GPU, вы увидите, что стоимость её аренды почти в 150 раз выше, чем классической версии CPU-only. Это значит, что раздача даже по одной собственной виртуалке, как это принято в других областях разработки, становится экономически невыгодной. -
Нестабильно.
GPU всё ещё остаются довольно капризными. Если что-то работает на одной модели, не значит, что это автоматически сработает и на другой. -
Сложно.
Кроме того, современные LLM-модели очень большие. Если вы работаете, например, с LLM, у которой несколько миллиардов параметров (что по современным меркам очень мало), вам уже нужно больше одного GPU. Возможно, даже несколько серверов по 8 GPU в каждом.
ML-инженерам нужны очень разные конфигурации железа, чтобы проверять свои идеи и применять их в реальном обучении. Что-то можно сделать и на уменьшенной версии желаемой модели и одном GPU, а где-то нужно будет гораздо больше GPU. При этом для некоторых задач GPU вообще не нужны.
Можно прибегать к простому способу и каждый раз создавать себе новую виртуалку или держать все возможные её виды под любые сетапы, но это будет неэффективно и неудобно.
В Яндексе мы сначала стали использовать коммунальные виртуалки. Команды выделяли себе несколько общих виртуалок и «жили» в них, как в коммунальных квартирах, со всеми вытекающими последствиями. Например, у каждой такой коммунальной виртуалки был чат, где «живущие» в ней ML-инженеры налаживали свой быт, выясняли отношения и все вместе сидели без дела, когда их хост физически ломался в дата-центре.
Командам самим приходилось делить свободные GPU, как и все другие ресурсы внутри виртуальных машин. Сообщение «Пожалуйста, почистите диск!!!» стало неотъемлемой частью рабочего процесса.
Почему коммунальные виртуалки не сработали
Очевидная идея собрать все GPU из виртуалок и придумать механизмы и правила, по которым этот shared-кластер сможет существовать, не сработала. Вот несколько главных причин, почему в итоге работать с таким решением оказалось крайне неудобно.
Во-первых, в ходе разработки ML-инженеру нужно довольно часто менять железо, с которым он работает. Вот пример типичного сценария:
- Пока человек просто пишет не связанный напрямую с ML код и хочет проверить, что он отрабатывает без ошибок, GPU не нужен.
- Для того чтобы сделать другой большой кусок кода, достаточно одного GPU.
- Чтобы работать с параллельным обучением, нужно уже несколько GPU.
- Если требуется выжать из железа максимум, нужен уже тот GPU, на котором модель будет в итоге учиться, и, как правило, он самый дорогой.
Во-вторых, ключевое отличие от привычного шеринга в том, что специалисту для работы нужно не только железо, но и множество других сущностей: код, библиотеки, модели, датасеты, настройки IDE, переменные окружения и т. д.
Если, например, при шеринге электросамокатов все девайсы практически идентично выполняют свою задачу, то случай с GPU больше напоминает совместную аренду квартиры. Даже если вам и смогут выдать точно такую же квартиру, но с дополнительной комнатой, мы все знаем, как непросто перенести все вещи и разложить их так, чтобы новое помещение стало хотя бы примерно похоже на ваш дом. С GPU ситуация такая же, и скорость переезда тоже очень важна.
Если переезд между разным железом будет сложным и неудобным, это отнимет много времени и сил у ML-инженеров, которые они могли бы потратить на работу. Кроме того, если обустраивать нужное железо тяжело или долго, каждому конкретному ML-инженеру выгодно держать такой ценный ресурс у себя как можно дольше.
Выход есть: Dev Cluster
Для того чтобы решить сложности работы с коммунальными виртуалками, мы создали Dev Cluster. Это технология, которая делает разработку на GPU удобной. Dev Cluster представляет собой решение в виде Managed GPU Cluster. Используя его, ML-инженеры могут не думать про состояние инфраструктуры, поломки и про то, как делить ресурсы внутри команды. Dev Cluster сделает это автоматически. Больше не нужно просить в чате почистить диск и освободить карточки.
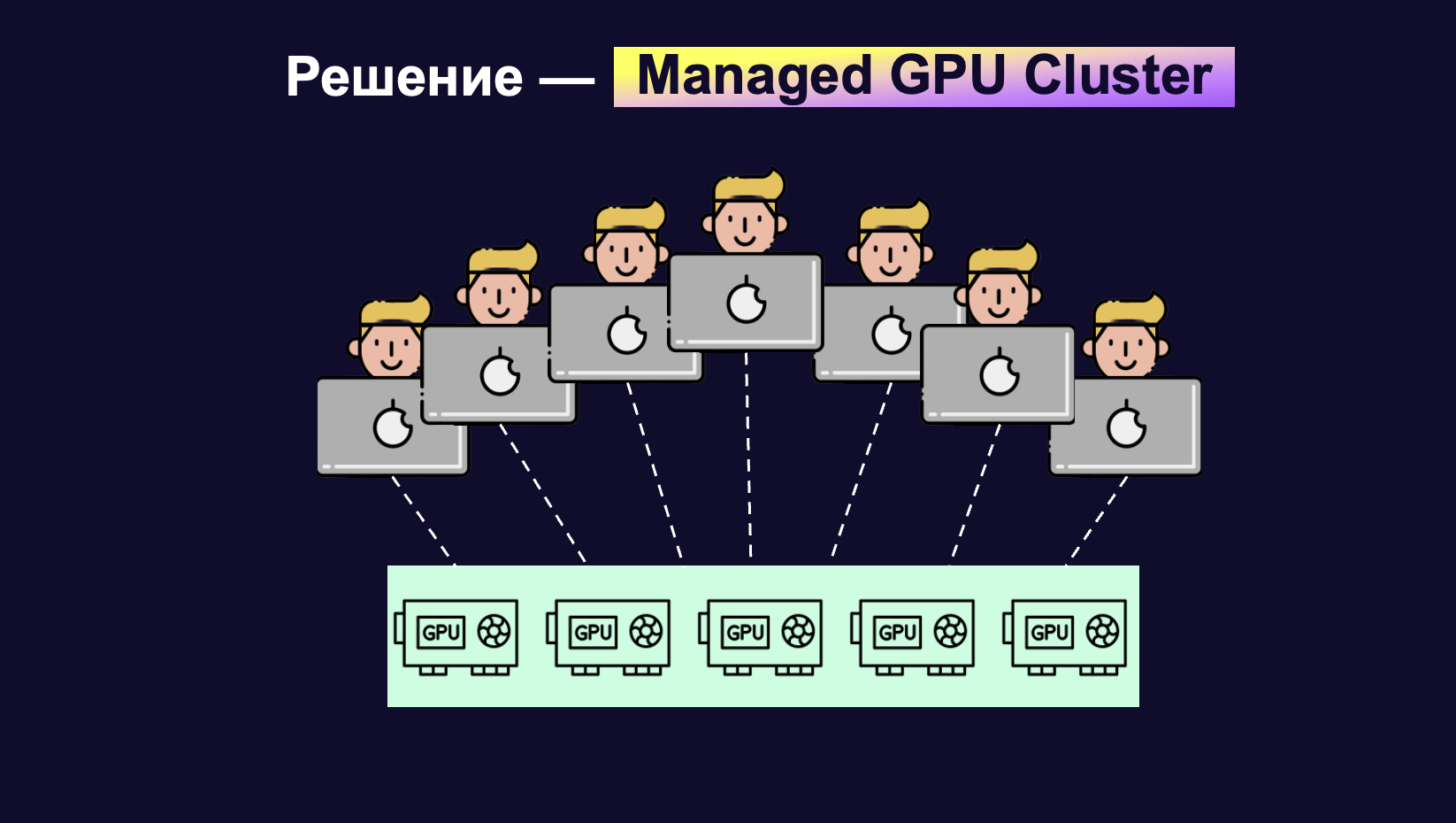
Dev Cluster — это инструмент, который предоставляет контейнеры и обеспечивает шеринг GPU для локальной разработки на CPU и GPU. С его помощью можно бесшовно переезжать с железа без GPU на железо с ним или наоборот, а также переключаться между разработкой и YTsaurus.
YTsaurus — наша платформа распределённого хранения и обработки больших данных с открытым исходным кодом. Это одна из основных инфраструктурных BigData-систем, разработанных в Яндексе. В Dev Cluster проще делать отладку в обычных контейнерах, но потом на больших объёмах экономически выгоднее запускать операции обучения в YTsaurus.
В любой ML-разработке GPU нужны далеко не всегда, и такое решение позволяет не занимать дорогой ресурс, пока ML-инженер пишет код или перекладывает данные.
Мы научили наш Dev Cluster подменять GPU таким образом, чтобы это было практически незаметно для разработчика, и делать это очень быстро. Нажимая несколько кнопок, пользователь получает сетап, идентичный тому, который у него был раньше, но уже с новым железом.
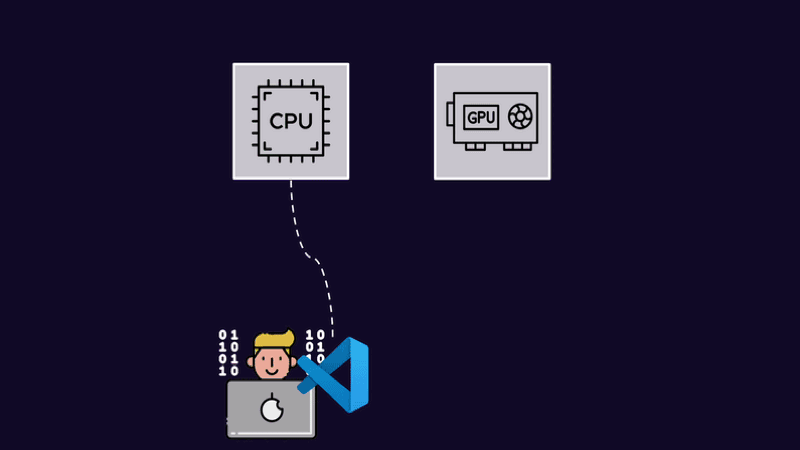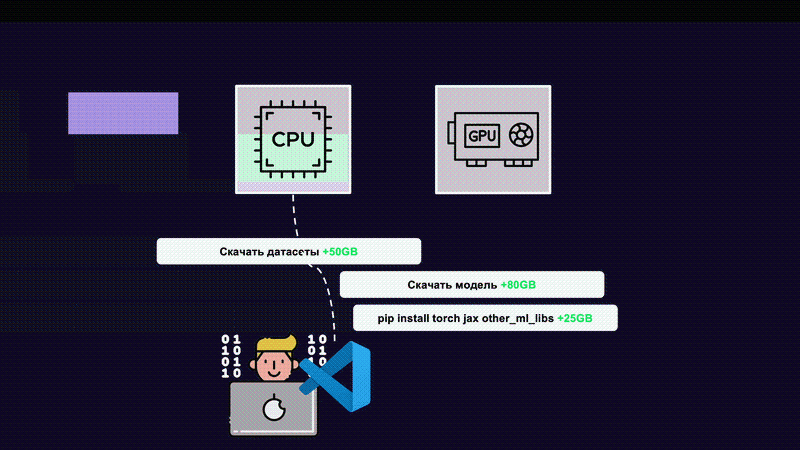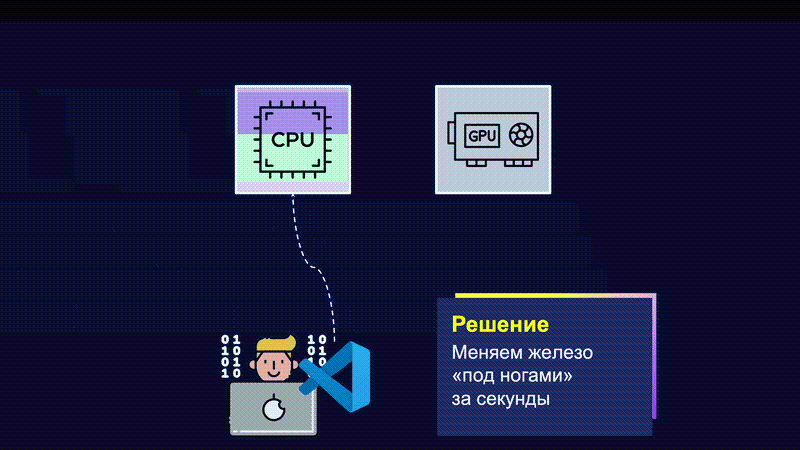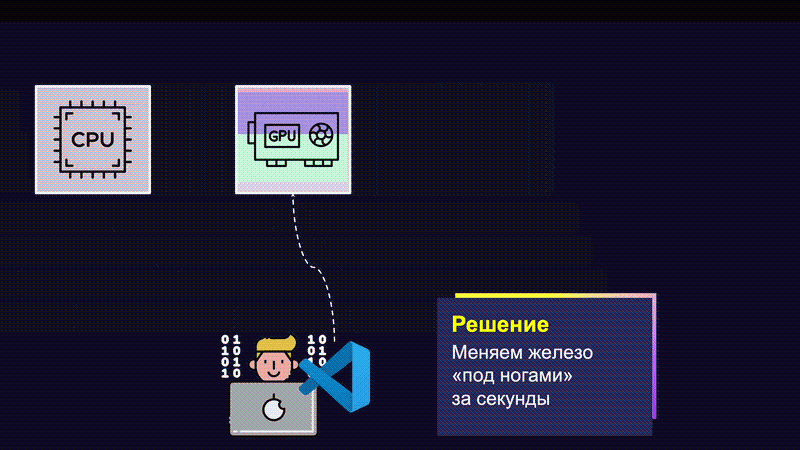
Наверняка вы могли подумать о том, зачем создавать такие сложные механизмы. Ведь можно сделать квоты, отбор неиспользуемого железа и доску антипочёта для «злоупотребляющих» ML-инженеров. В чём-то вы правы: в Dev Cluster есть всё, кроме последнего.
Квоты и автоматика отбора ненужного железа созданы для удобства пользователей. Мы не хотим усложнять всё и искать способы, как бороться с нечестным использованием системы. Поэтому постарались сделать так, чтобы и специалисты по машинному обучению, и компания, которая тратит деньги на GPU, получали от этого максимальную пользу.
Dev Cluster как позволяет повысить доступность ресурсов для всех, так и, например, даёт возможность обмениваться разными типами карт между командами. Например, он может помочь в ситуации, когда у одной команды есть только V100, но сейчас для работы им нужна A100, которая в этот момент не нужна другой команде.
Что из себя представляет Dev Cluster под капотом
Dev Cluster состоит из нескольких основных компонентов:
-
Net Switch — сетевого маршрутизатора, предоставляющего фиксированный IP-адрес контейнеру и перенаправляющего его трафик на текущую аллокацию, т. е. на размещённый на конкретном хосте контейнер.
-
-Запускаемых на хостах агентов, которые позволяют, например, управлять пользовательскими контейнерами.
При запуске агент собирает информацию о доступных аппаратных ресурсах, открывает сокет для приёма команд и регистрируется в базе данных менеджера.
Агенты управляют кешем базовых образов на хосте (благодаря менеджеру Dev Cluster агент узнаёт, какие слои актуальны для аллокации, удаляет ненужные и загружает требуемые), управляют персистентным хранилищем данных на хосте (например, отправляют и принимают дельта-слои другим хостам при переносе контейнера), работают с жизненным циклом контейнера (например, перезапускают его в случае падения).
-
Remote Storage, который хранит большие файлы, чтобы не переносить их вместе с контейнером. При запуске нового контейнера, агент монтирует пользовательский Volume Remote Storage.
-
Менеджера и планировщика Dev Cluster Control Plane — компонента, организующего взаимодействие агентов и свитчей Dev Cluster и оптимизирующего использование ресурсов в рамках заданных ограничений. Он хранит стейт для всех компонентов и отслеживает их состояние; распределяет контейнеры по хостам, регистрирует их в DNS.
-
Клиентов. Основные сценарии сейчас реализуются через CLI, дополнительно есть фронтенд с базовыми функциями управления контейнерами.
Основная логика реализована на стеке: Go, gRPC, PostgreSQL, Porto.
Как GPU-managed-кластер выглядит для ML-инженера
Для полноты картины давайте вместе пройдём путь ML-разработчика и решим его реальную задачу с помощью нашего нового инструмента. Попробуем запустить популярный фреймворк для Reinforcement Learning — VERL.
Шаг 1. Создадим workspace
На начальном этапе необходимо просто скачать репозиторий к себе в workspace и научить VERL читать данные из нашего storage — YTsaurus.
Для этого нужно пойти на нашу ML-платформу, которая используется внутри для всевозможных ML-задач, — Underdeep.
За несколько кликов мы создадим себе workspace с нужной конфигурацией по железу.
Шаг 2. Скачаем VERL и начнём разработку
Наш workspace создался за несколько секунд и уже готов к работе. Остаётся подключиться к нему через VS Code и работать с workspace как с самой обычной виртуальной машиной. Скачаем на неё нужный фреймворк для тестов.
Шаг 3. Возьмём один GPU
Когда работа с чтением данных закончена, наступает время взять один GPU.
Перемещаем рабочее окружение и получаем один GPU V100. Выводим отчёт о доступных CUDA девайсах
Шаг 4. Пойдём на обед
Предположим, что пришло время обеда и занимать GPU смысла нет, как и другие ресурсы. Тем не менее хочется оставить работу в максимально быстром доступе, а не полностью выключить workspace и сохранить все результаты работы (не только код, а весь workspace целиком) в persistent-хранилище.
«Сдуть» workspace можно, нажав всего на одну кнопку.
Шаг 5. Протестируем параллельное обучение на двух GPU
Вернувшись с обеда, переходим на два GPU. Здесь проходим те же шаги, что и для получения одного GPU.
Шаг 6. Закончим работу
Представим, что работу над этой задачей мы полностью закончили, а этот workspace может понадобиться нам, но не скоро. Для этого существует механизм Suspend, который полностью отключает workspace от железа, сериализует его и кладёт в persistent-хранилище. Это тоже делается кликом на одну кнопку.
Главный итог: повысили удовлетворённость ML-инженеров почти в два раза
Разработку Dev Cluster мы начали для решения вполне конкретной задачи. Наши ML-инженеры жаловались на то, как им сложно и неэффективно работать с коммунальными GPU-виртуалками. Мы проводили опрос о нашей ML-инфраструктуре чуть больше года назад, и разработка на виртуалках заняла уверенное последнее место, получив в среднем 2,7 балла из 5.
После внедрения Dev Cluster, мы провели ещё один опрос, который показал хорошие результаты. Ребята отмечали, что разрабатывать код обучения и дебажить его стало гораздо удобнее.
В ближайшем будущем мы планируем дальше развивать функциональность Dev Cluster.
Dev Cluster — это часть нашей ML-платформы, которая отвечает за весь цикл ML-разработки в Яндексе. В следующих постах продолжим рассказывать про другие её компоненты.

В этой статье:
- Вызовы машинного обучения: как пошарить GPU на всех
- Коммунальные виртуалки, эврика! Или нет?
- Почему коммунальные виртуалки не сработали
- Выход есть: Dev Cluster
- Что из себя представляет Dev Cluster под капотом
- Как GPU managed-кластер выглядит для ML-инженера
- Главный итог: повысили удовлетворенность ML-инженеров почти в 2 раза