На странице команды можно найти подробную информацию о том, какими задачами мы занимаемся, каким стеком пользуемся, как внедряем собственные разработки и как попасть к нам в Storage.

От лапок паука к щупальцам осьминога. Зачем мы поменяли архитектуру объектного хранилища Яндекса
Александр Трушкин рассказывает об эволюции объектного хранилища Яндекса: почему понадобилось обновлять архитектуру стораджа, как справились с вызовами масштабирования, за счёт чего новая система работает быстрее и эффективнее.
3 марта 2026 г.
15 минут чтения
Для начала кратко расскажу о том, что такое объектное хранилище, как раньше была устроена его архитектура и какие минусы прежнего подхода к управлению стораджем побудили нас внедрить обновления.
Объектное хранилище: структура, требования, особенности
Объектное хранилище — тип хранилища, в котором единица загрузки данных представляет собой объект, определяемый уникальным идентификатором. В таком хранилище нет традиционной иерархии хранения объектов. Здесь используется плоское адресное пространство.
Основные сущности системы хранилища
- Шард — минимально доступная единица для записи каких‑либо объектов.
- Группа — контейнер для данных фиксированного размера. Чтобы повысить надёжность хранения, используется репликация. Один шард будет состоять из нескольких групп, число которых равно фактору репликации этого шарда.
- Namespace — контейнер для всех шардов пользователя, он изолирует объекты каждого пользователя.
Базовые требования к хранилищу
- Надёжность хранения данных: важно хранить и отдавать пользовательские данные без потерь.
- Эффективные запись и чтение: пользователи не должны испытывать сложности.
- Изоляция данных пользователей.
- Масштабируемость системы: объём данных постоянно растёт, что требует регулярного расширения хранилища новыми хостами с дисками.
Старая архитектура: как это работало раньше
- Первый слой — ноды Data Plane. Это сервис, который умеет только сохранять и отдавать данные. Здесь используется подход append‑only: все новые записи и изменения дописываются в конец диска. Это ускоряет последовательную запись и чтение, но добавляет необходимость периодически дефрагментировать удалённые данные (компактить).
- Второй слой — клиентская репликация на уровне Proxy‑сервиса (обслуживание запросов пользователя).
- Третий слой — сервис Control Plane: обслуживание, управление и сбор информации о кластере. Это «мозг» системы, он:
- запускает процессы синхронизации групп;
- запускает процессы дефрагментации (данные важно компактить, чтобы они занимали меньше места);
- перевозит данные с хостов, если требуется их вывести для обслуживания;
- занимается сбором статистики и информации о кластере (для грамотной балансировки нагрузки и равномерного распределения объёма данных).
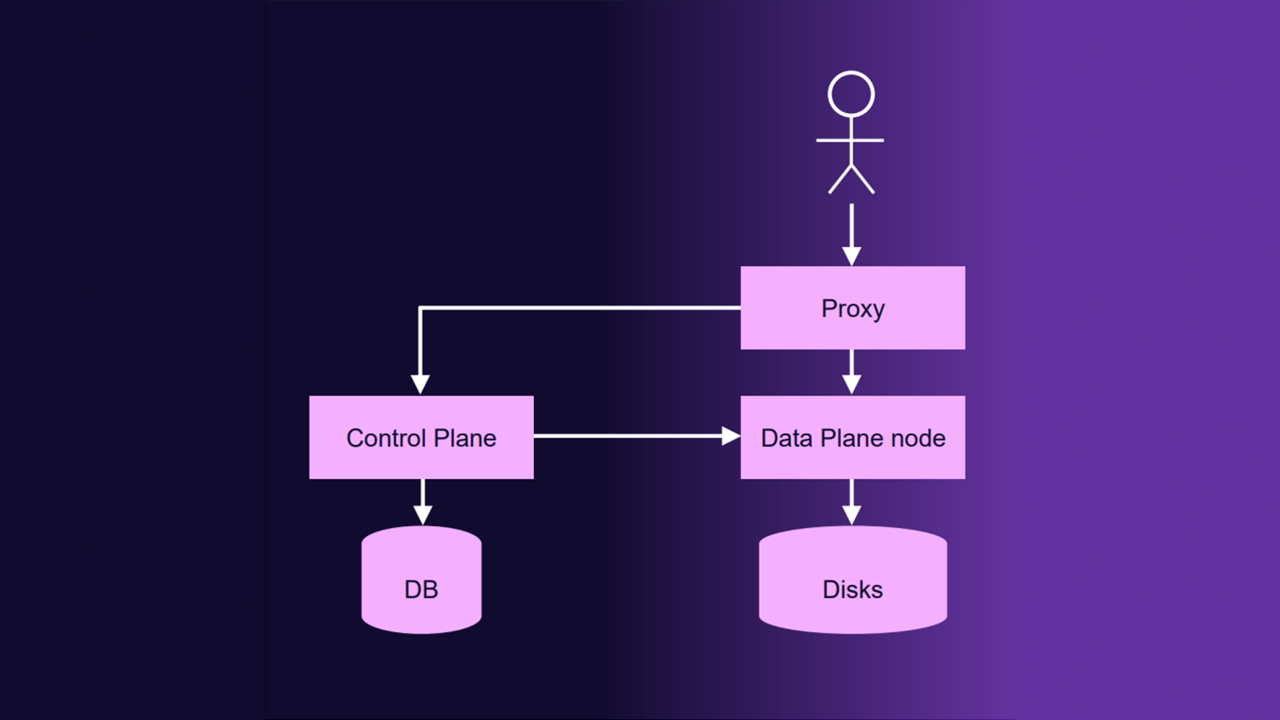
В итоге мы получали следующую архитектуру:
- Пользователь ходит в Proxy‑сервис (это его точка входа).
- Proxy ходит в Control Plane, чтобы понять, в какой шард ему идти для записи данных пользователя.
- Он получает от Control Plane всю необходимую информацию и идёт в Data Plane, выполняет репликацию и сохраняет данные в нужное количество нод.
- Также Control Plane ходит в ноды Data Plane, собирает информацию и обслуживает кластер.
Выглядело это так:
Плюсы прежнего подхода
- Простой слой хранения данных: система умеет только сохранять и отдавать, поэтому всё работает надёжно.
- Основная логика сосредоточена в Control Plane. Это удобно: у нас есть единый центр координации, который знает, что и как делать.
- Полный контроль над кластером.
- Система подходит для хранилищ малых и средних масштабов.
Минусы прежнего подхода
- Архитектура с централизованным управлением. Единая точка отказа в этой архитектуре — это Control Plane, так как он управляет всеми процессами по обслуживанию кластера. Control Plane отвечает и за балансировку записи в кластере, указывая Proxy‑слою, куда записывать данные пользователя. Если Control Plane выходит из строя, могут возникнуть проблемы с дефрагментацией и синхронизацией.
- Линейный рост сложности обслуживания кластера. С увеличением количества хостов в кластере потребуется больше времени на то, чтобы Control Plane обошёл кластер и собрал статистику.
- Замедление времени реакции на нештатные ситуации с ростом количества хостов.
- Императивный подход в обслуживании кластера. Зачастую процессы обслуживания кластера — это либо ручные действия, либо действия администраторов, либо скрипты. Они могут быть запрограммированы в виде алгоритма, но все они выполняются пошагово. Контроль за целостностью системы также лежит на исполнителе — будь то администратор или Control Plane.

Объём данных растёт — пора менять подход
Прежний подход вполне рабочий, но в системах уровня Яндекса имеет ограничения в масштабировании: хранилища скоро должны были вырасти на порядок, а то и на два. Стало ясно: чтобы успешно масштабироваться и качественно обслуживать кластер, нам нужен другой подход к проектированию хранилища.
Итак, у нас был Data Plane — централизованный компонент, который всем управляет стратегически. Необходимо было добавить в ноды Data Plane немного «мозгов», дополнив стратегию тактикой. Тогда умный Data Plane сможет самостоятельно принимать определённые решения, а Control Plane будет заниматься только стратегическим планированием того, как должен выглядеть кластер.
Сравнивая старую и новую архитектуру хранилища, приведу такую аналогию. Пауку, чтобы выполнить определённое действие, например, подвинуть камешек, нужно подумать об этом и затем лапкой сделать. У осьминога же нервная система настолько развита, что нейроны находятся не только в голове, но и в щупальцах. За счёт этого щупальца становятся вполне автономными для того, чтобы выполнять действия или принимать решения. Поэтому осьминогу достаточно подумать о том, что нужно сделать с камешком, и выбрать щупальце, а щупальце само придёт к результату.
Вот как эти отличия можно изобразить схематично:
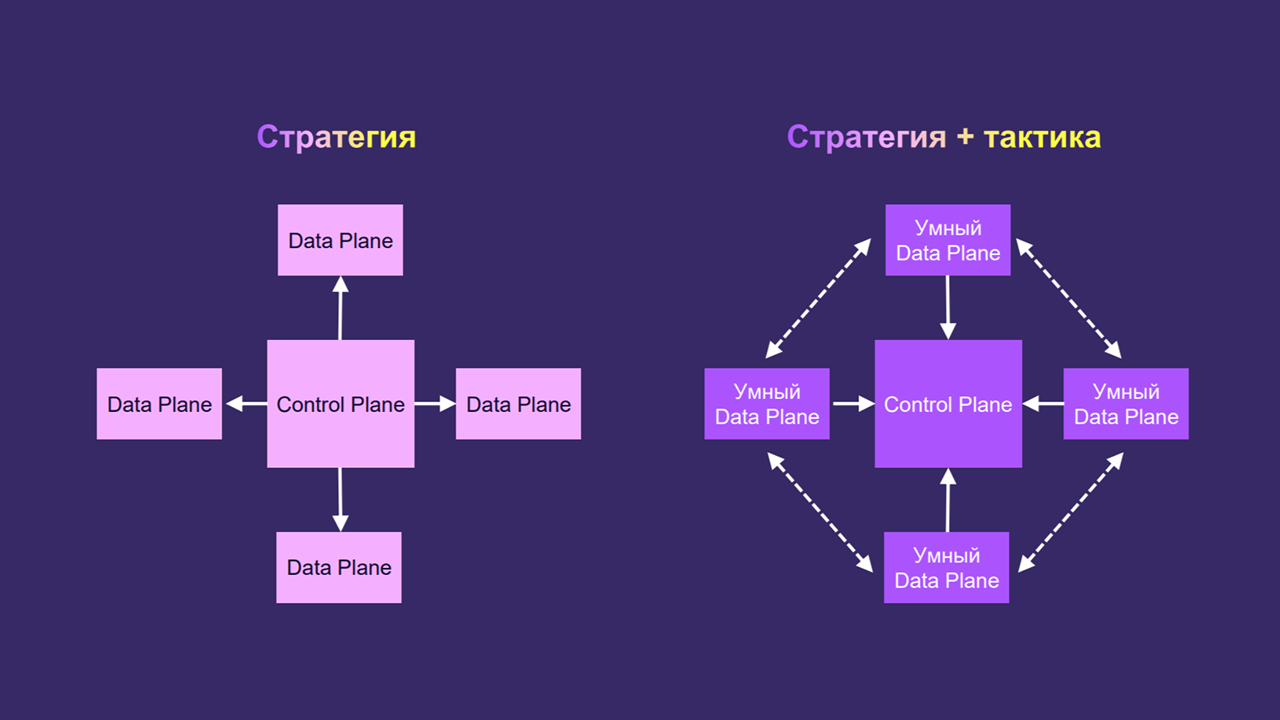
Слева — Control Plane, «мозг» всей нашей системы. Если ему что‑то потребуется от Data Plane, он придёт туда и выполнит нужные команды. После этого система обретает желаемое состояние.
Справа — новая усложнённая схема, отражающая аналогию с осьминогом. У нас есть умный Data Plane. Он сам принимает определённые решения и выступает автономной единицей. В то же время Data Plane ходит в Control Plane, чтобы понять, какие действия выполнить дальше.
Новые возможности для масштабирования
Изменения помогли нам получить довольно самостоятельный Data Plane. Вот его возможности:
-
Ответственность за обслуживание данных (без внешнего управления). Если ноде Data Plane надо выполнить дефрагментацию, она запускает её, не дожидаясь команды от Control Plane.
-
Ответственность за выбор группы: не привязываем шард к конкретной группе, а связываем его с хостом. В этом нам помогает декларативный подход.
-
Знание о топологии каждого шарда на ноде. Каждый шард образуется в свой самостоятельный Raft‑кластер. Все группы — участники этого шарда — являются участниками Raft‑кластера и следят за консистентностью данных. Если какая‑то группа выйдет из строя и потом вернётся в кластер, она «поймёт», что отстала от других, и запустит процесс синхронизации.
-
Service Discovery. Группы могут самостоятельно объединяться в шарды с помощью Service Discovery и знания о топологии каждого шарда.
Таким образом, мы разгрузили Control Plane:
-
Data Plane самостоятельно ходит в Control Plane и рассказывает о своём состоянии: загруженность дисков, сети, наличие свободных и занятых групп. Как часто это происходит? Мы предусмотрели фиксированную настраиваемую периодичность, сейчас это 15 секунд.
-
Control Plane в ответ сообщает Data Plane об изменениях в топологии, требующих внимания.
Кроме того, у Control Plane есть фоновая задача, которая следит за тем, как регулярно приходит Data Plane с синхронизацией. Если время превышает лимит, Control Plane понимает, что с нодой неполадки, и запускает процессы синхронизации и добавления новых групп взамен ушедших.
Следить за состоянием кластера нам помогает декларативный подход. Этот принцип проектирования и управления системой предполагает, что вместо выполнения отдельных шагов для достижения желаемого состояния описывается это состояние. Все действия выполняются атомарно. Вот пример такого описания:

Таким образом, мы просто описываем состояние системы. Например, говорим, что у пользователя должен быть шард с ID номер один, а фактор репликации — равен трём. Добавляем ограничение: каждая группа должна находиться в своём дата‑центре. Это позволяет надёжно хранить данные: при отказе дата‑центра информация не потеряется.
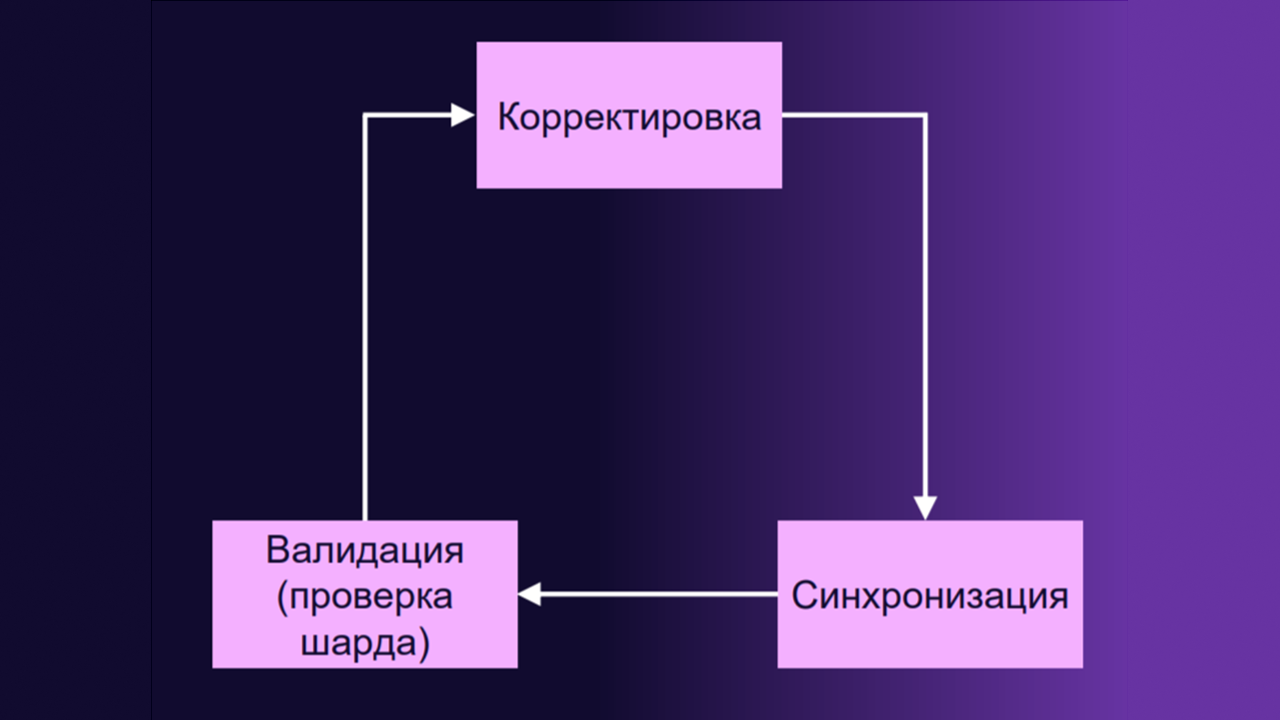
Цикл согласования в новой системе
Рассмотрим пример. У нас есть описание шарда с тремя группами, которые нормально функционируют. В какой‑то момент ломается диск, группа выходит из строя. Data Plane на этапе синхронизации приходит в Control Plane и говорит, что группа потерялась. Control Plane видит, что в шарде должно быть три группы, а по факту их только две, и запускает процесс корректировки.
Цикл делится на три этапа:
- Мы видим, что шард требует внимания (об этом сообщает Data Plane).
- Сравниваем состояние шарда и переходим к корректировке: видим, что шарду не хватает одной группы, запускаем процессы взвешивания всего кластера и находим идеально подходящий хост (на основе объёма свободного места или нагрузки на сеть, диск).
- Фиксируем изменения в базе и на этапе синхронизации отправляем информацию в Data Plane. Далее Data Plane находит нужный шард через Service Discovery и подключается к соседям в группы.
Схема цикла построена так:
Как выглядит новая архитектура
На этой схеме можно увидеть изменения в архитектуре объектного хранилища.
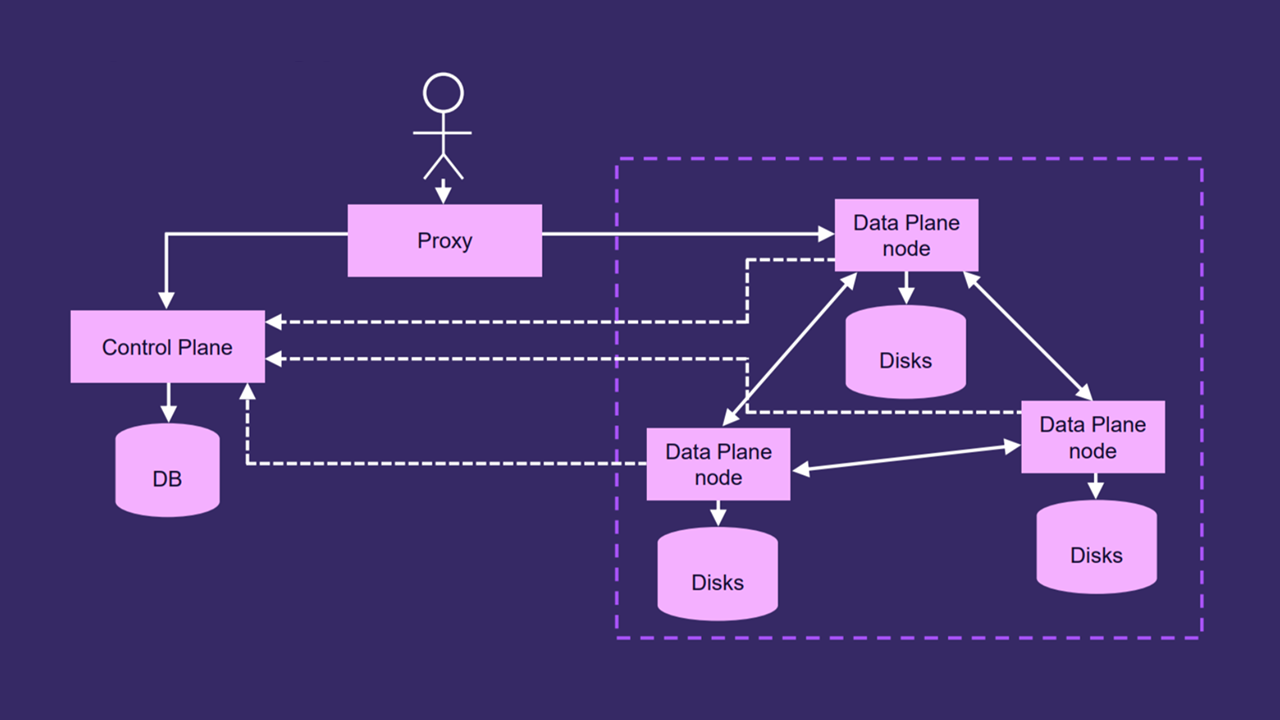
-
Пользователь по‑прежнему ходит в Proxy, а Proxy — в Control Plane, чтобы получать веса.
-
Proxy больше не требуется самостоятельно реплицировать данные: благодаря объединённому шарду в Raft‑кластер там достаточно сходить в любую из нод, и объект автоматически отреплицируется в две соседние ноды. После этого придёт коммит, и мы ответим пользователю, что его файл успешно записан.
-
Направление синхронизации изменилось: теперь ноды Data Plane ходят в Control Plane и сообщают о своём состоянии.
От императивного к декларативному подходу: быстрее и проще
Обновив архитектуру, мы ушли от императивного подхода в управлении кластером, когда Control Plane сам всё пошагово выполнял и следил за состоянием системы.
Декларативный подход дал следующие преимущества:
-
Мы избавились от команд типа «Добавь эту группу в шард» или «Создай новый шард». Теперь мы просто описываем, что шард должен быть в таком‑то Namespace и иметь три реплики. Система и умные ноды Data Plane самостоятельно организуются в шард и будут доступны на записи.
-
Ускорился сбор шардов благодаря тому, что в Control Plane остаётся только их описание. Нам достаточно сказать: «Создай новый шард» — не нужно ждать, пока Control Plane найдёт группы и последовательно выполнит команды для сбора шарда.
-
Теперь кластер обслуживать проще: наша система стала самовосстанавливающейся и практически не требует внимания со стороны человека или Control Plane как исполнителя. Умный Data Plane не только ускоряет операции, но и снижает нагрузку на Control Plane. Мы также избавились от линейного роста сложностей со сбором статистики и обслуживанием кластера, что позволяет хорошо масштабироваться.
-
Ускорилась реакция на нештатные ситуации. Раньше, когда Control Plane последовательно опрашивал весь кластер (даже с 10–100 хостами), период синхронизации составлял около минуты. При 3000 хостах обновление информации занимало около 10 минут. С новым подходом синхронизация происходит каждые 15 секунд, поэтому мы быстрее узнаём о проблемах и принимаем решения. Это позволяет повысить надёжность хранения данных.


